Forecasting Household Energy Usage
TL;DR
I used my household energy usage to build forecasting models and put the models into production using APIs and docker.
About
When I worked at Deloitte global finance leadership tasked us with adding intelligence to the sales pipeline. I architected a suite of financial models, including forecasting, probability of success, and time to close models. This work was implemented using Databricks and was one our teams biggest hits.
The time series work was modular and generalized code, so that it could easily extend to any configuration. By this I mean that eventually it wasn’t just the global CFO that wanted our forecast, but local member firm leaders as well, such as Deloitte UK leadership.
The down side to killer projects at work is that there isn’t anything tangible to show recruiters or hiring managers. So, I decided to replicate the architecture of the Deloitte project and improve it.
One thing I’ve noticed over the years is that much of the work data scientists create goes unused. I think this is why the machine-learning-engineer branch of data science formed. It’s not enough to create models. The missing piece was putting the models into production. That’s why in this project production is a key element.
Design
The diagram below illustrates at a high-level the overall scope of work.
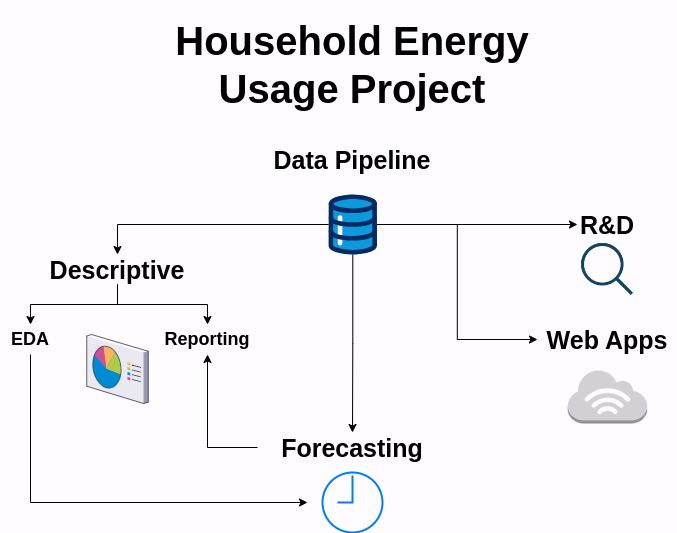
Data
The data pipeline for the household energy project has two types of data, energy usage and historical weather. The data is housed in a private AWS S3 bucket. See the post under Data section in Projects for more details about the pipeline.
Planning
Edit: As of October 26, 2024 the Python portion is complete and in production. I’ve decided to leave the planning
As of October 9th, 2024 this project is still in the planning phase because as my late father in-law used to say, before starting any project you should, “sit on your butt and think.”
For this project I will create forecasting models in Python and R. Yes, you read that correctly, this is a multilingual project! I am also exploring if Julia has time series forecasting capabilities. I started learning Julia c. 2021 and enjoy using it.
I will use statistical, machine learning, and deep learning models. In Python, this will be accomplished via the Nixtla suite of packages. In R, I will use fable andmodeltimeviatidymodels`.
The challenge I’m thinking through is how to easily split training the models and forecasting. A neat trick that I came up with on the Deloitte project is to store all of the models in a module. This module can be imported into the training and forecasting workflows, respectively. The neat thing about this solution is that it avoids repetition. I also think it’s cleaner this way because everything is centralized.
Below is an example project structure:
project-root
- py
- src
- models
- stats.py
- ml.py
- dl.py
- scripts
- training
- main.py
- forecasting
- main.py
- main.pyIn this structure the models are modules that the training and forecasting workflows or pipelines leverage.
The main module will have a toggle to switch between training and forecasting. As this is a passion project and the forecasts aren’t used for anything, I don’t need to update the models frequently. I think that having main flip between training and forecasting is better than manually executing things. For example, ./py/main.py will import ./py/training/main.py and ./py/forecasting/main.py. Each of the children main files will be mini-control centers for their respective workflows.
Some thought about production. My goal is to put this work into production, and for that I need a way to interact with the models easily. To accomplish this I want to create a fastAPI for the python forecasts and a plumber API for the R forecasts. I’ll likely package in a container using docker or podman.
I’ll host the container on a spare desktop I’ve beefed up for these purposes - 16 cores, 64 GB RAM, and a NVIDIA GPU. When there’s new data and I want to obtain the latest forecasts I’ll spin up my spare desktop and ping it.
Reality
Generally, thorough planning is helpful but it’s helpful to be flexible to changes that arise during the work.
Design
The work was designed as conceptually planned. I used modules to encapsulate the models and there are training and forecasting processes. The details however are slightly different.
project-root
- py
- notebooks
- training.qmd
- src
- aws
- data_processing
- forecasting
- forecasting.py
- logistics
- models
- stats.py
- ml.py
- scripts
- data
- forecasting
- train.py
- forecast.pySrc
src is a collection of standalone modules that define functions or classes. Most of the modules are standard.
The forecasting.py module within forecasting is interesting though. Nixtla, the time series meta-module used in this work is great. One annoyance though is that the various forecasting classes have different methods. For example, StatsForecast uses .forecast(h) to generate forecasts while MLForecast uses .predict(h). I had to build a an abstraction layer on top of Nixtla so that I only had to call .forecast(h) to generate forecasts.
To accomplish this, the forecasting.py module uses isinstance() to apply the correct methods. When the model is of type StatsForecast my abstraction layer applies the correct Nixtla method.
Scripts
The scripts section compiles the functions and classes in src into usable workflows. For example, the scripts/data/data.py module imports the src/aws/aws.py and src/data_processing/prep.py modules. The aws.py module defines a class to work with AWS and the prep.py module defines a class of data processing steps methods.
These modules are imported in various work streams, such as notebooks/training.qmd. The idea was to centralize things as much as possible to avoid repetition.
Models
The plan was to explore statistical, ML, and deep learning models. However, only statistical and ML models were used. This was partly due to the desire to build an SLC/MVP and continue onto other projects.
I also created a baseline set of models called src/models/baseline.py. These are Nixtla statsforecast models: historical average and naive forecast. These models are used in the training process/
Training
I’m quite proud about the training process. I used a parameterized Quarto template (i.e., notebooks/training.qmd) to define the training process.
The train.py file uses docopt to create a command-line interface to the training procedure. The usual flags are present, --help and --version, but I created a custom argument to define which models get trained.
python train.py fit stats ml autoMLAs far as I could find online, this is one of the few examples of automated parameterized Quarto reports with Python.
Each call to train.py creates an HTML report with the name of the model and the date, e.g., autoML-2024-10-25.html. This way there is a running log of training runs.
Training details
Most of the code needed to generate a forecast is the same across Nixtla model types (i.e., stats, ml, etc.). Initially, I had separate Quarto documents for each modeling type. However, I noticed the similarities between the notebooks so I decided to use a single template with parameters.
When the process is kicked of via python train.py fit ... the process imports whatever is passed to .... There are checks to ensure that whatever follows fit exists. For example, python train.py fit foo would return an error because module src/models/foo.py does not exist.
The goal of training is to find the best models. Each model module in src/models defines a list of models to explore. For instance, stats.py defines ~10 models.
The training process imports all of the models including the baseline models. In order to be considered for production, all models must perform better than the best baseline model, the benchmark. For each model module (stats, ML, autoML) the models are fitted and compared to the benchmark. The model name or alias of the best models is saved in a YAML config file. This is the output of the training process and will come into play later.
The data is split into training and test sets. The split cutoff is a parameter currently set to 6 months by default.
Hyperparameter tuning
I’d be remiss not to discuss hyperparameter tuning. The two main modeling modules are stats.py and ml.py. There is one modeling module, autoML.py.
The autoML.py contains the same list of models as ml.py. However, the autoML.py module has methods to perform hyperparameter tuning without user input. This is useful because I would otherwise have to manually build code to perform hyperparameter tuning. The training process imports autoML.py and let’s it do its thing. The parameters of the best models (i.e., those with test results better than benchmark) are printed. I manually update the models in ml.py with the results of training autoML.py
Production
Once the training process has been executed and the config files have been updated, it’s time for production.
API
I used fastAPI to create an endpoint for the forecasting process. The endpoint is defined in forecast.py. This file imports a pre-defined function, scripts/forecating/forecast.py. This function imports the my generalized forecasting class, the config files, etc. to produce a forecast. The periods to forecast is the only parameter of the API.
Docker
I used docker to create the isolated environment.
The server
I have a household server for hosting internal websites and running analytical workflows. I remote into the server, git pull to get the latest updates.
I perform two operations on the server, the training process and hosting the forecasting API.
Training
The training process creates HTML reports that need to be synced (i.e., git add ... git push).
Forecasting API
I build the docker image locally on the server.
Retrieving the latest forecast
From a terminal I ping my home’s server. The forecast API has one argument, \(h\) that specifies how many days in the future to forecast.
curl http://server-address:8081/forecast/?h=5In moments, the latest forecast arrives.
{"forecast":[{"unique_id":"home","ds":"2024-09-21T00:00:00","model":"ridge","forecast":37.09393282803336,"lower":28.79194596792015,"upper":47.78974836170291},...]}Next steps
The next step is to build a dashboard that pings the forecasting API programmatically.